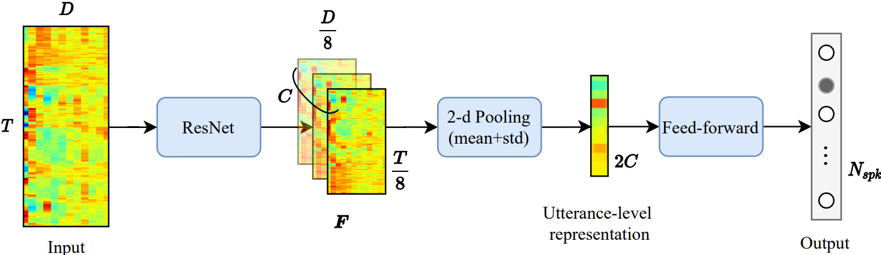
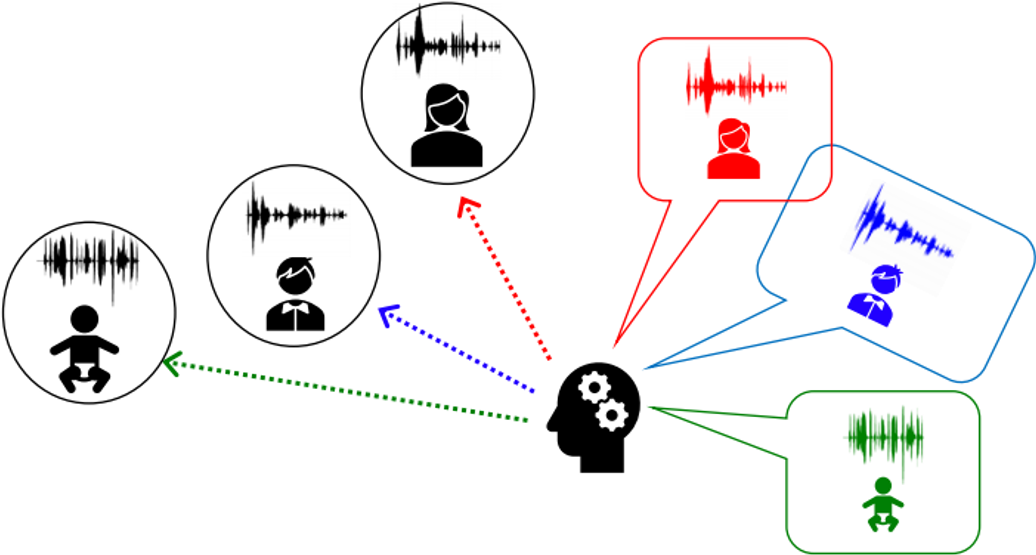
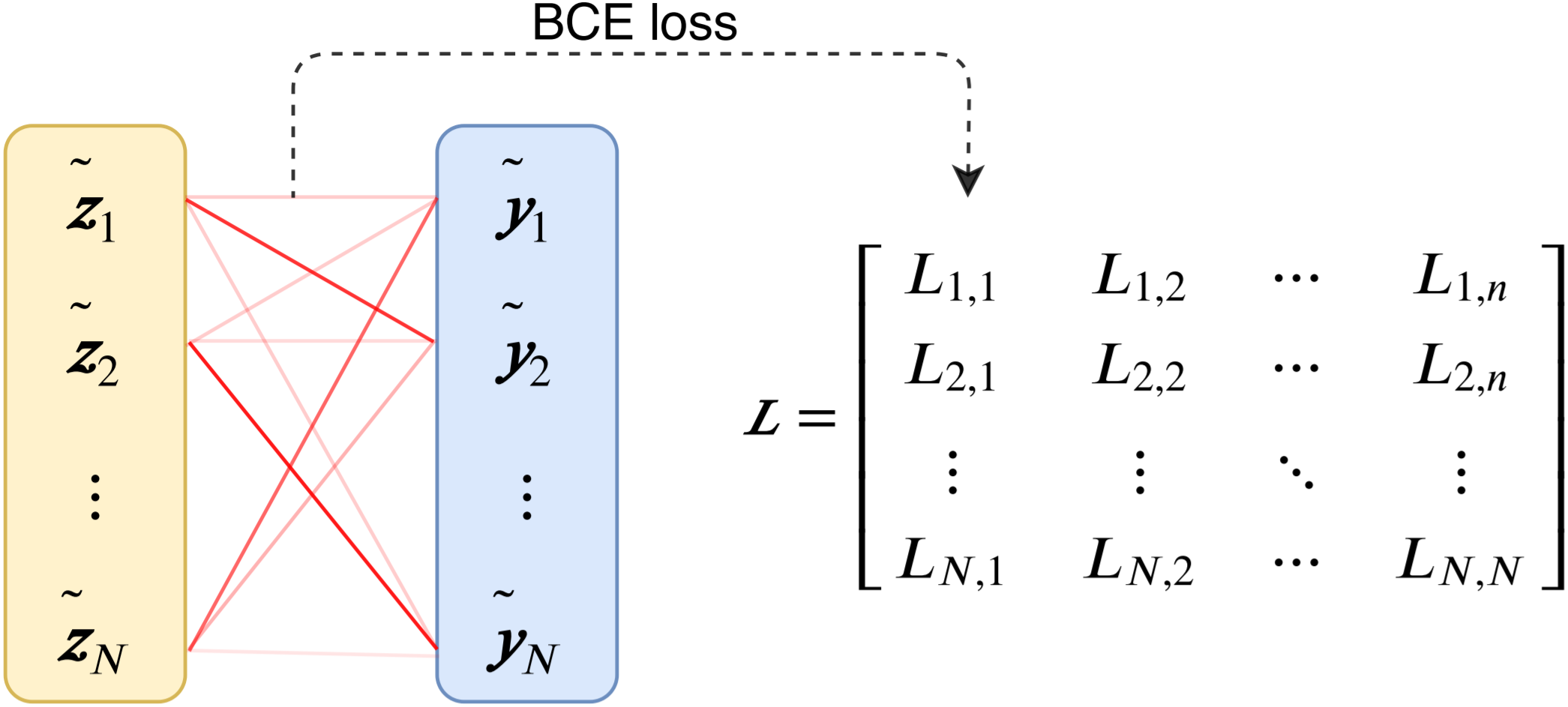
I am a fourth-year CS Ph.D. student at UC Berkeley, advised by Gopala Anumanchipalli. I am a part of Berkeley Artificial Intelligence Research (BAIR) Lab, where I have been fortunate to collaborate with Andrew Owens.
Previously, I had the privilege to work with Hang Zhao from Tsinghua University and Ming Li from Duke University.
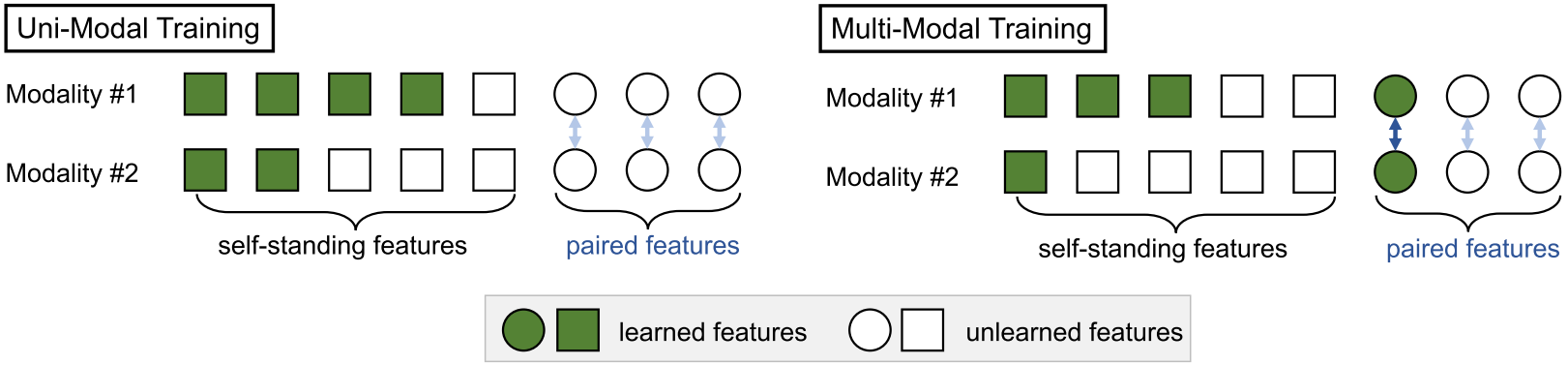
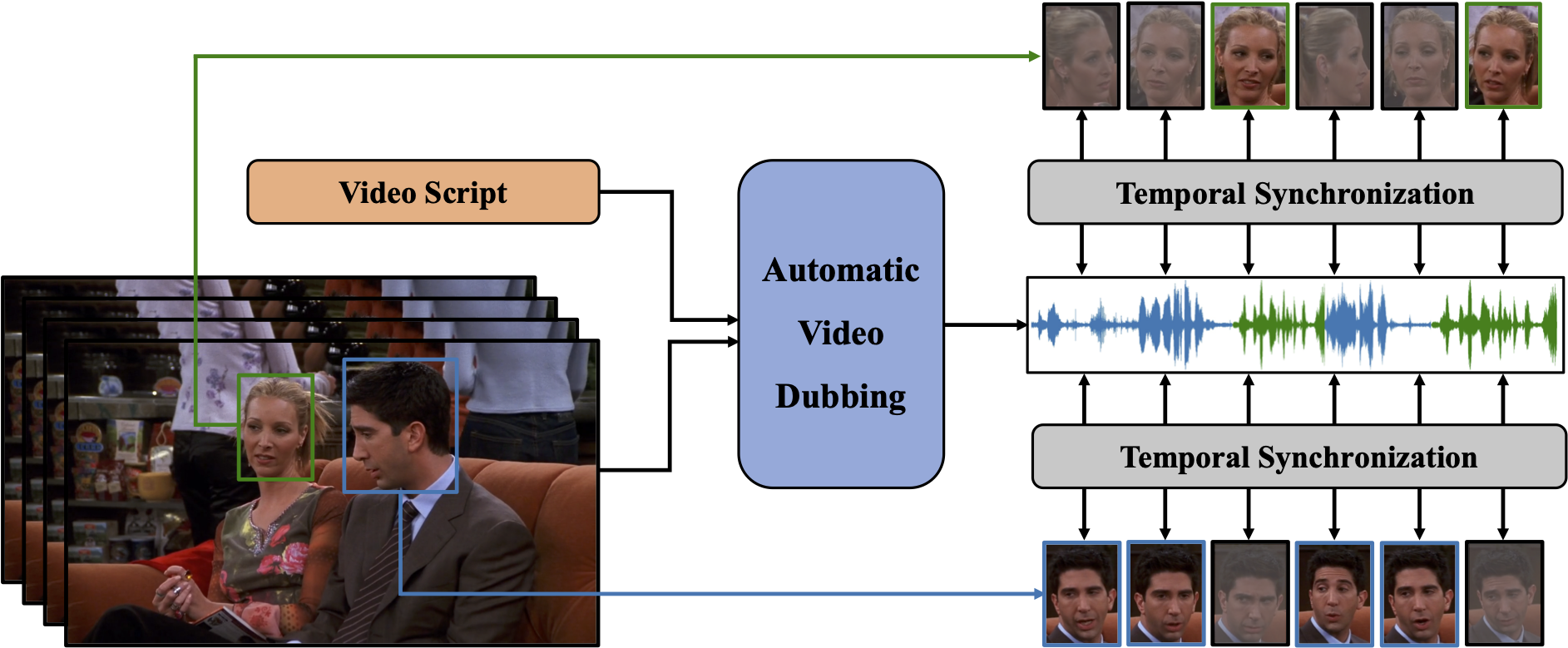
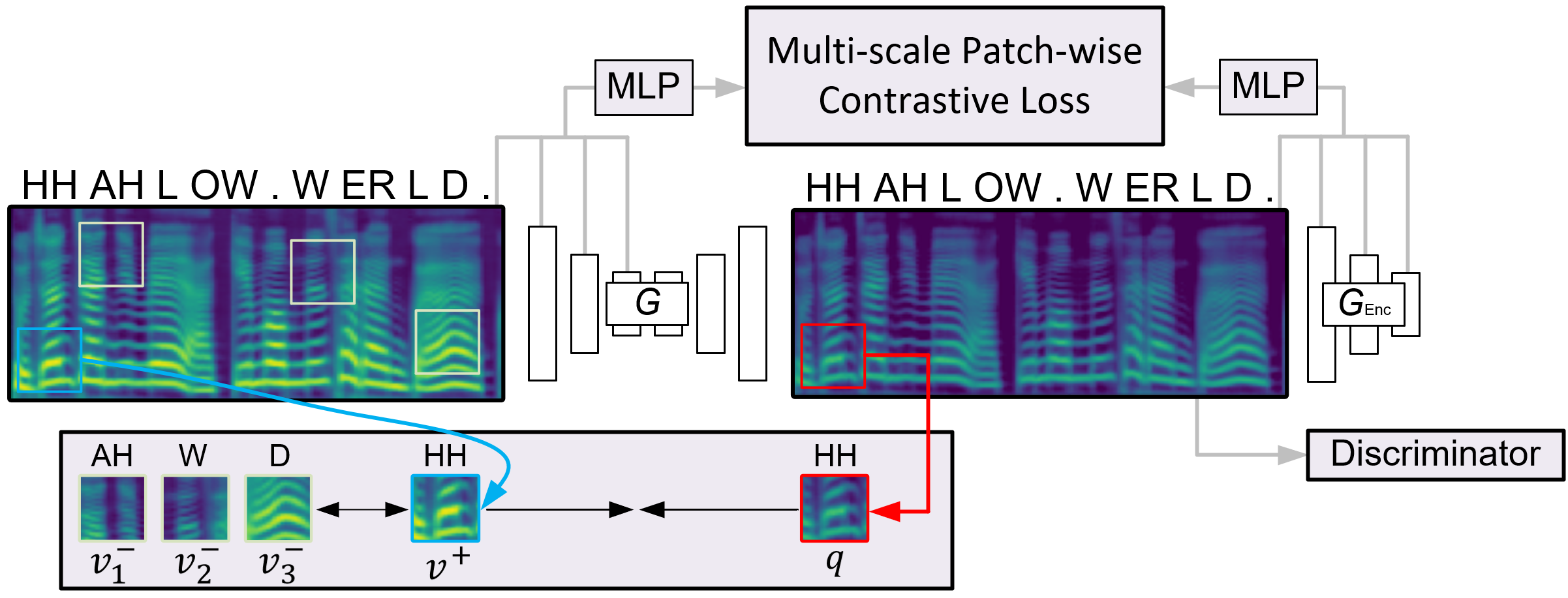
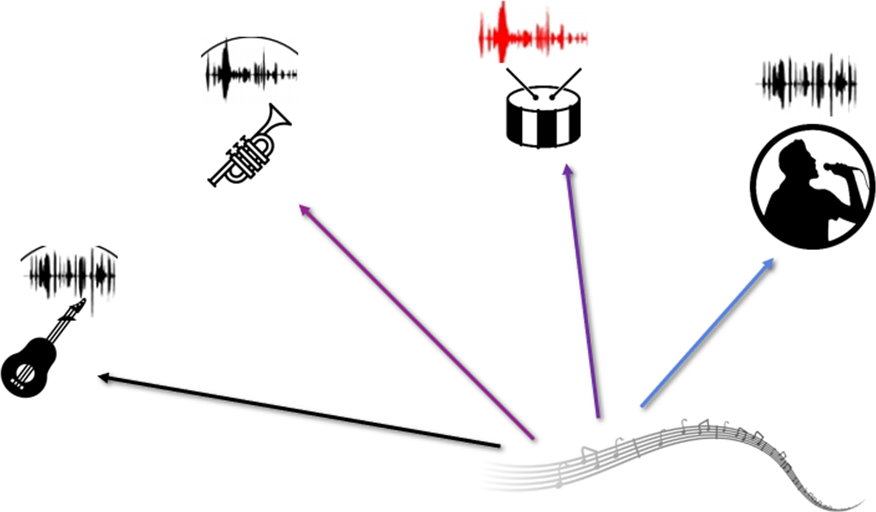
My research uses sound as a window into physical common sense, revealing how objects and scenes are composed, behave, and interact in ways vision and language alone may not capture. I am grateful to be supported by the Sony Research Award.