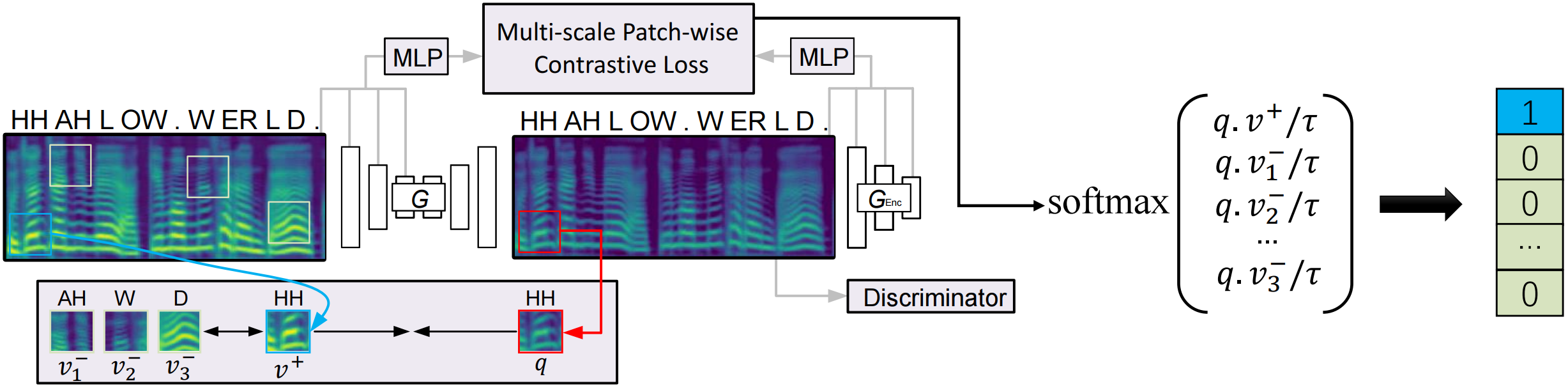
This webpage is to show some listening examples for our proposed CVC and the baseline CycleGAN-VC[1] and VAE-VC[2]. Compared to previous CycleGAN-based methods, CVC only requires an efficient one-way GAN training by taking the advantage of contrastive learning. When it comes to nonparallel one-to-one voice conversion, CVC is on par or better than CycleGAN and VAE while effectively reducing training time. CVC further demonstrates superior performance in many-to-one voice conversion, enabling the conversion from unseen speakers.
3-Minutes Demo Video
One-to-one Voice Conversion
F-F: female→female | F-M: female→male | M-M: male→male | M-F: male→female
F→F (p225 → p228)
F→M (p225 → p256)
M→M (p270 → p256)
M→F (p270 → p228)
Many-to-one Voice Conversion (Seen)
Seen-source-speaker to seen-target-speaker conversion.
F→F (p261 → p228)
F→F (p225 → p228)
F→M (p261 → p256)
F→M (p225 → p256)
M→M (p227 → p256)
M→M (p270 → p256)
M→F (p227 → p228)
M→F (p270 → p228)
Many-to-one Voice Conversion (Unseen)
Unseen-source-speaker to seen-target-speaker conversion.
F→F (p244 → p228)
F→M (p244 → p256)
M→M (p252 → p256)
M→F (p252 → p228)
Comparison
Many-to-one CVC compared to one-to-one CVC.
F→F (p225 → p228)
F→M (p225 → p256)
M→M (p270 → p256)
M→F (p270 → p228)
References
- T. Kaneko, H. Kameoka, K. Tanaka, and N. Hojo, "CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-spectrogram Conversion," in Interspeech, 2020, pp. 2017–2021.
- C-C. Hsu, H-T. Hwang, Y-C. Wu, Y. Tsao, and H-M. Wang, "Voice conversion from non-parallel corpora using variational auto-encoder," in APSIPA, 2016, pp. 1–6.