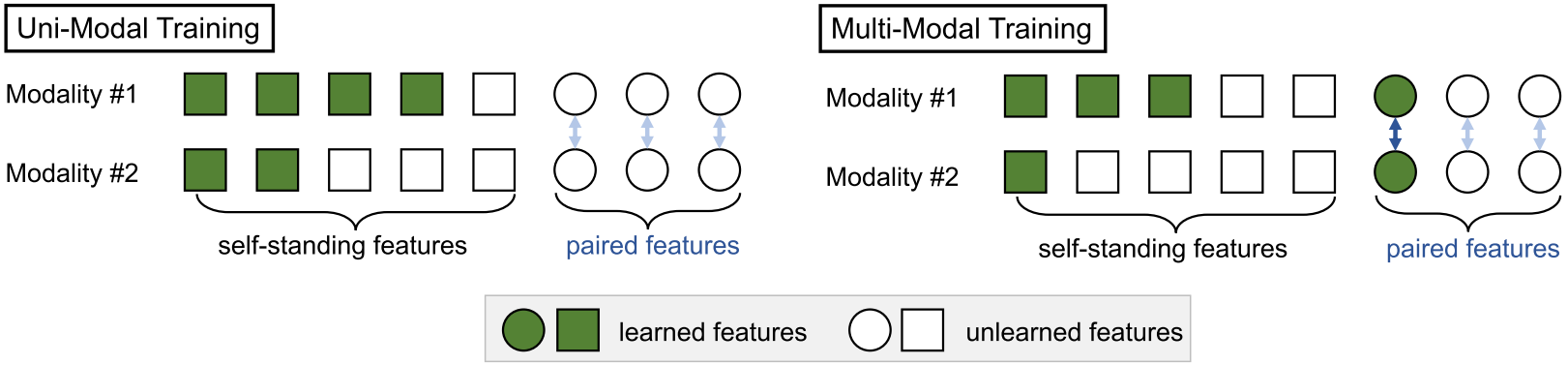
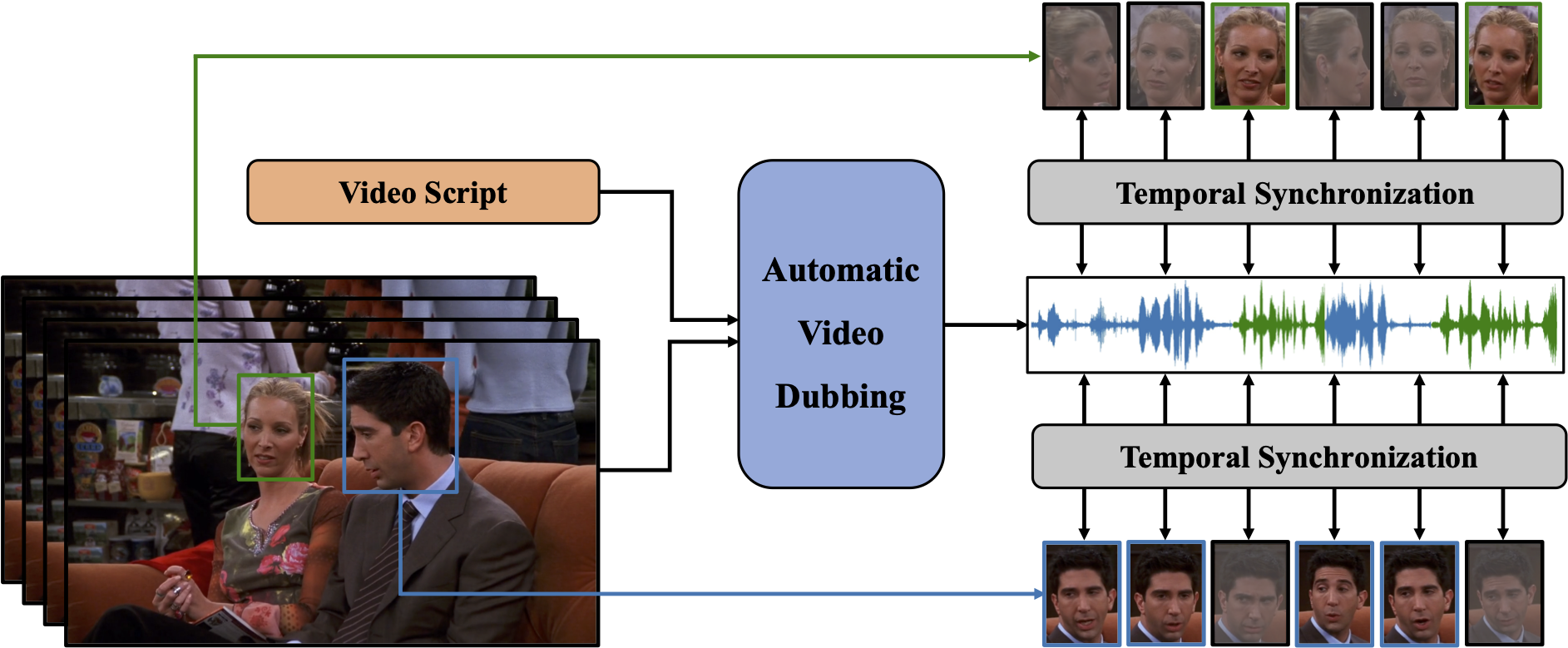
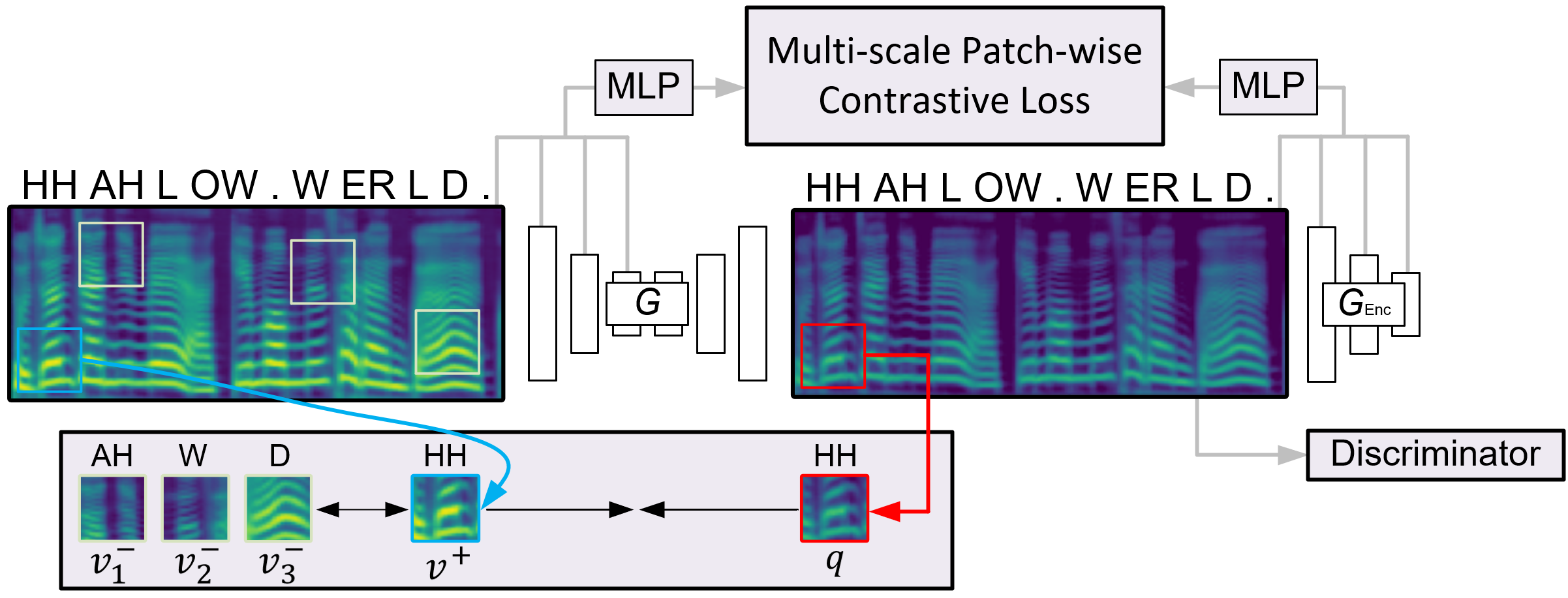
Benchmarking Single-Factor Physical Video-to-Audio Generation
Tingle Li, Siddharth Gururani, Kevin J. Shih, Gantavya Bhatt, Sang-gil Lee, Zhifeng Kong, Arushi Goel, Gopala Anumanchipalli, Ming-Yu Liu
CVPR, 2026
A benchmark for evaluating physically-grounded video-to-audio generation.