TL;DR: We interactively generate sounds specific to user-selected objects within complex visual scenes.

Abstract
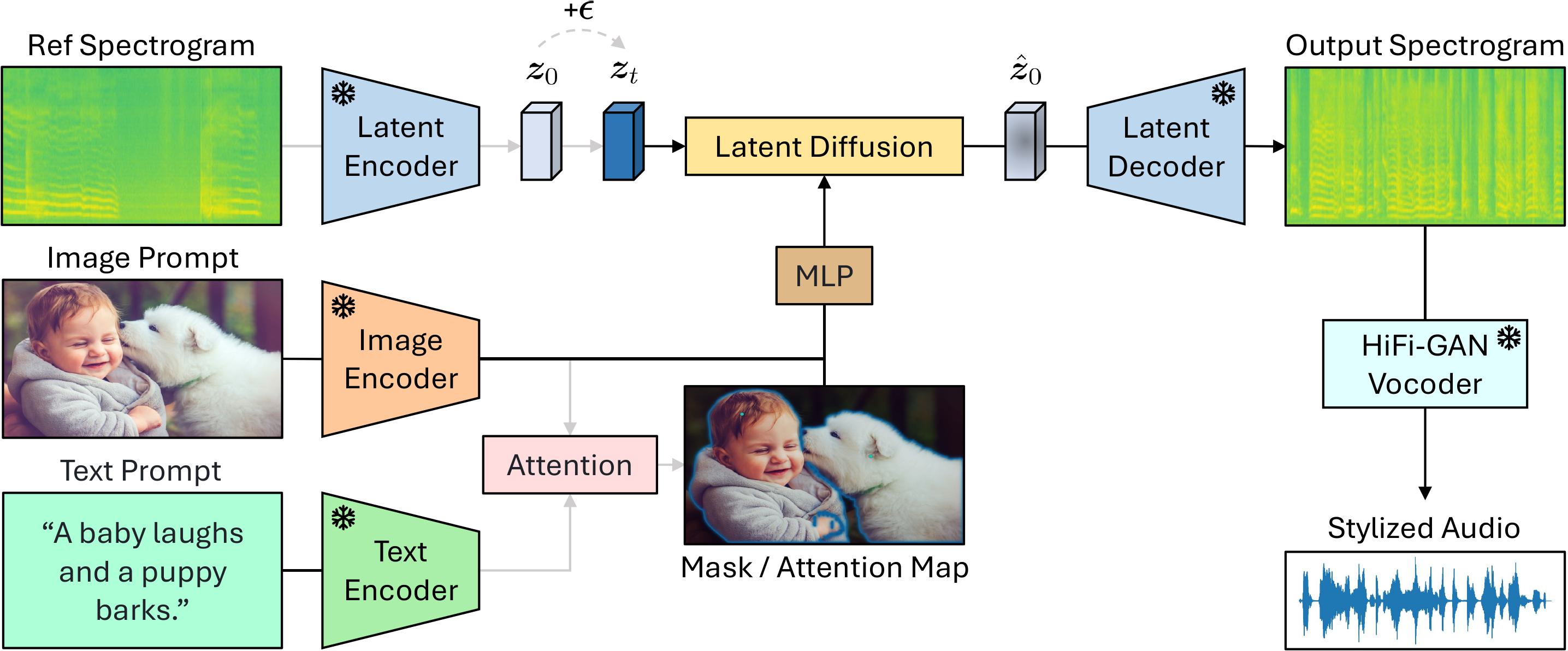
Generating accurate sounds for complex audio-visual scenes is challenging, especially in the presence of multiple objects and sound sources. In this paper, we propose an interactive object-aware audio generation model that grounds sound generation in user-selected visual objects within images. Our method integrates object-centric learning into a conditional latent diffusion model, which learns to associate image regions with their corresponding sounds through multi-modal attention. At test time, our model employs image segmentation to allow users to interactively generate sounds at the object level. We theoretically validate that our attention mechanism functionally approximates test-time segmentation masks, ensuring the generated audio aligns with selected objects. Quantitative and qualitative evaluations show that our model outperforms baselines, achieving better alignment between objects and their associated sounds.
Compositional Sound Generation
Click on video to unmute/mute. Use arrows to navigate.
Sound Adaptation to Visual Texture Changes
Click on video to unmute/mute. Use arrows to navigate.
Generation Results with In-Domain Examples
Click on video to unmute/mute. Use arrows to navigate.
Model Architecture
BibTeX
@inproceedings{li2025sounding,
title = {Sounding that Object: Interactive Object-Aware Image to Audio Generation},
author = {Li, Tingle and Huang, Baihe and Zhuang, Xiaobin and Jia, Dongya and Chen, Jiawei and Wang, Yuping and Chen, Zhuo and Anumanchipalli, Gopala and Wang, Yuxuan},
booktitle = {ICML},
year = {2025},
}We thank Ziyang Chen, Hao-Wen Dong, Yisi Liu, and Zhikang Dong for their helpful discussions, the anonymous reviewers for their valuable feedback, and Nerfies for open sourcing this website template.